R တွင် bivariate ခွဲခြမ်းစိတ်ဖြာနည်း (ဥပမာများနှင့်အတူ)
bivariate analysis ဟူသော ဝေါဟာရသည် ကိန်းရှင်နှစ်ခု၏ ခွဲခြမ်းစိတ်ဖြာမှုကို ရည်ညွှန်းသည်။ ရှေ့ဆက် “ bi” သည် “ နှစ်ခု” ဖြစ်သောကြောင့်၎င်းကိုသင်မှတ်မိနိုင်သည်။
bivariate ခွဲခြမ်းစိတ်ဖြာခြင်း၏ပန်းတိုင်မှာ variable နှစ်ခုကြားရှိ ဆက်နွယ်မှုကို နားလည်ရန်ဖြစ်သည်။
bivariate ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန် ဘုံနည်းလမ်းသုံးမျိုးရှိသည်။
1. တိမ်ညွှန်
2. ဆက်စပ်ကိန်းများ
3. ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု
အောက်ဖော်ပြပါ ဥပမာသည် ကိန်းရှင်နှစ်ခုတွင် အချက်အလက်များပါရှိသော အောက်ပါဒေတာအစုံကို အသုံးပြု၍ အဆိုပါ bivariate ခွဲခြမ်းစိတ်ဖြာမှု အမျိုးအစားတစ်ခုစီကို မည်သို့လုပ်ဆောင်ရမည်ကို သရုပ်ပြသည်- (1) လေ့လာချိန်နာရီများနှင့် (2) မတူညီသော ကျောင်းသား 20 မှ ရရှိသော စာမေးပွဲရမှတ်များ-
#create data frame df <- data. frame (hours=c(1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 6, 7, 8), score=c(75, 66, 68, 74, 78, 72, 85, 82, 90, 82, 80, 88, 85, 90, 92, 94, 94, 88, 91, 96)) #view first six rows of data frame head(df) hours score 1 1 75 2 1 66 3 1 68 4 2 74 5 2 78 6 2 72
1. တိမ်ညွှန်
R တွင် လေ့လာထားသော နာရီများနှင့် စာမေးပွဲအဆင့်ကို ခွဲခြမ်းစိတ်ဖြာရန် အောက်ပါ syntax ကို အသုံးပြုနိုင်ပါသည်။
#create scatterplot of hours studied vs. exam score plot(df$hours, df$score, pch= 16 , col=' steelblue ', main=' Hours Studied vs. Exam Score ', xlab=' Hours Studied ', ylab=' Exam Score ')
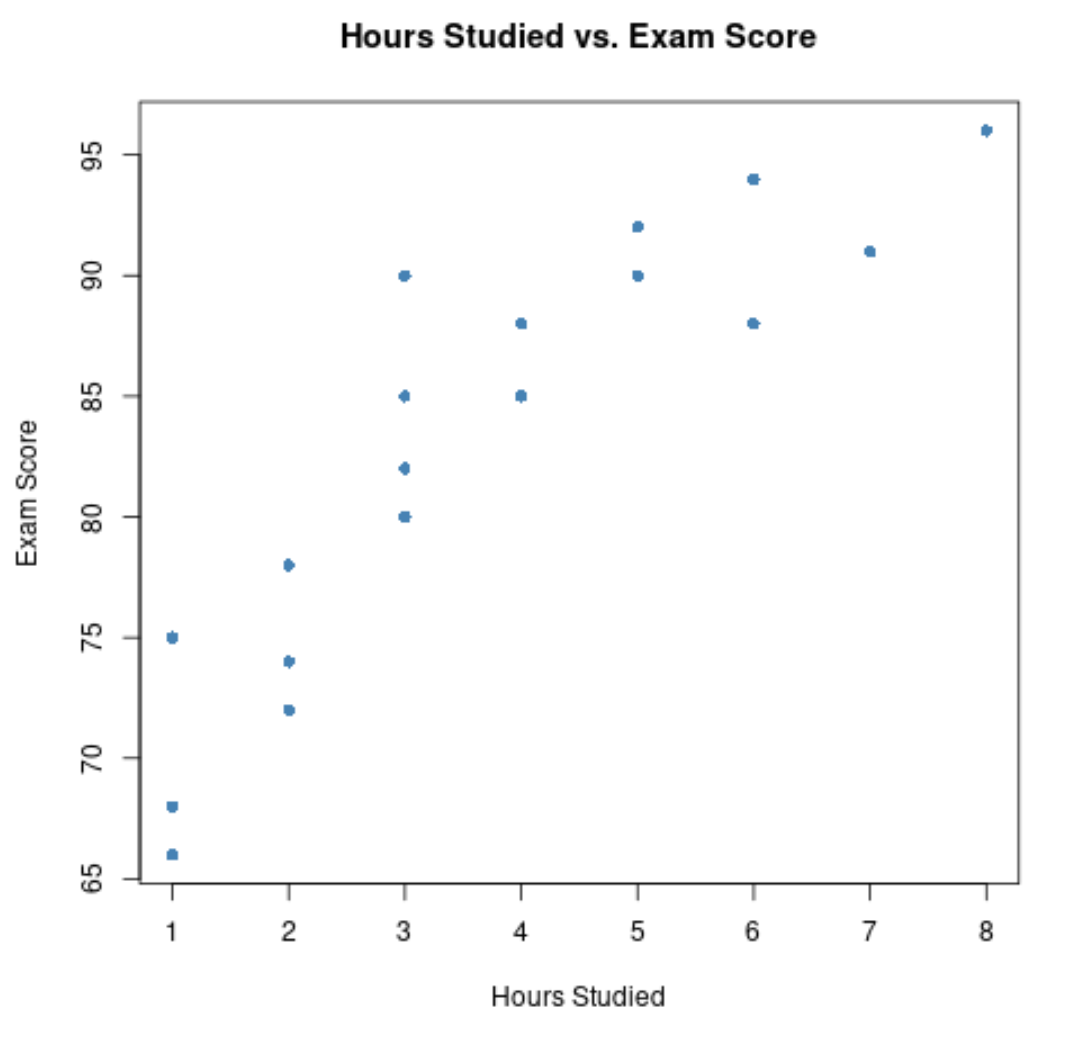
x-axis သည် လေ့လာထားသောနာရီများကိုပြသပြီး y-axis သည် စာမေးပွဲတွင်ရရှိသောအဆင့်ကိုပြသသည်။
ကိန်းရှင်နှစ်ခုကြားတွင် အပြုသဘောဆောင်သော ဆက်နွယ်မှုရှိကြောင်း ဂရပ်က ဖော်ပြသည်- လေ့လာမှု နာရီအရေအတွက် တိုးလာသည်နှင့်အမျှ စာမေးပွဲရမှတ်များလည်း တိုးလာတတ်သည်။
2. ဆက်စပ်ကိန်းများ
Pearson ဆက်စပ်ဆက်စပ်ကိန်းတစ်ခုသည် ကိန်းရှင်နှစ်ခုကြားရှိ မျဉ်းကြောင်းဆက်နွယ်မှုကို တွက်ဆရန်နည်းလမ်းတစ်ခုဖြစ်သည်။
ကိန်းရှင်နှစ်ခုကြားရှိ Pearson ဆက်စပ်ကိန်းကို တွက်ချက်ရန် R ရှိ cor() လုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်သည်။
#calculate correlation between hours studied and exam score received
cor(df$hours, df$score)
[1] 0.891306
ဆက်စပ်ကိန်းဂဏန်းသည် 0.891 ဖြစ်လာသည်။
ဤတန်ဖိုးသည် 1 နှင့် နီးစပ်သောကြောင့် သင်ကြားသည့်နာရီနှင့် စာမေးပွဲအဆင့်ကြားတွင် ခိုင်မာသော အပြုသဘောဆက်စပ်မှုကို ညွှန်ပြသည်။
3. ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု
ရိုးရှင်းသော linear regression သည် ကိန်းရှင်နှစ်ခုကြားရှိ အတိအကျဆက်နွယ်မှုကို နားလည်ရန် အသုံးပြုနိုင်သည့် ဒေတာအစုတစ်ခု၏ “ အံဝင်ခွင်ကျ” မျဉ်း၏ညီမျှခြင်းကို ရှာဖွေရန် ကျွန်ုပ်တို့အသုံးပြုနိုင်သည့် ကိန်းဂဏန်းဆိုင်ရာနည်းလမ်းတစ်ခုဖြစ်သည်။
နာရီပေါင်းများစွာ လေ့လာပြီး စာမေးပွဲရလဒ်များရရှိသော ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံကို အံကိုက်ရန်အတွက် R တွင် lm() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
#fit simple linear regression model fit <- lm(score ~ hours, data=df) #view summary of model summary(fit) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -6,920 -3,927 1,309 1,903 9,385 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 69.0734 1.9651 35.15 < 2nd-16 *** hours 3.8471 0.4613 8.34 1.35e-07 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 4.171 on 18 degrees of freedom Multiple R-squared: 0.7944, Adjusted R-squared: 0.783 F-statistic: 69.56 on 1 and 18 DF, p-value: 1.347e-07
တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုညီမျှခြင်းမှာ-
စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(စာသင်ချိန်)
ထပ်လောင်းလေ့လာထားသောနာရီတိုင်းသည် စာမေးပွဲရမှတ်တွင် ပျမ်းမျှ 3.8471 တိုးလာခြင်းနှင့် ဆက်စပ်နေကြောင်း ၎င်းကဆိုသည်။
ကျောင်းသားတစ်ဦးရရှိမည့်ရမှတ်ကို ခန့်မှန်းရန် တပ်ဆင်ထားသည့် ဆုတ်ယုတ်မှုညီမျှခြင်းကိုလည်း အသုံးပြု၍ လေ့လာခဲ့သည့် စုစုပေါင်းနာရီအရေအတွက်အပေါ် မူတည်၍ ကျောင်းသားတစ်ဦးရရှိမည့်ရမှတ်ကို ခန့်မှန်းနိုင်သည်။
ဥပမာအားဖြင့်၊ ၃ နာရီစာလေ့လာသော ကျောင်းသားသည် ရမှတ် 81.6147 ရသင့်သည် ။
- စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(စာသင်ချိန်)
- စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(3)
- စာမေးပွဲရလဒ် = 81.6147
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် bivariate ခွဲခြမ်းစိတ်ဖြာခြင်းဆိုင်ရာ နောက်ထပ်အချက်အလက်များကို ပေးဆောင်သည်-
Bivariate ခွဲခြမ်းစိတ်ဖြာခြင်းအတွက် နိဒါန်း
လက်တွေ့ဘဝတွင် bivariate data နမူနာ ၅ ခု
Simple Linear Regression နိဒါန်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။