
Comment tracer la distribution des valeurs de colonne dans Pandas
Vous pouvez utiliser les méthodes suivantes pour tracer une distribution de valeurs de colonne dans un DataFrame pandas :
Méthode 1 : tracer la distribution des valeurs dans une colonne
df['my_column'].plot(kind='kde')
Méthode 2 : tracer la distribution des valeurs dans une colonne, regroupées par une autre colonne
df.groupby('group_column')['values_column'].plot(kind='kde')
Les exemples suivants montrent comment utiliser chaque méthode en pratique avec le DataFrame pandas suivant :
import pandas as pd #create DataFrame df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], 'points': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print(df) team points 0 A 3 1 A 3 2 A 4 3 A 5 4 A 4 5 A 7 6 A 7 7 A 7 8 A 10 9 A 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
Exemple 1 : tracer la distribution des valeurs dans une colonne
Le code suivant montre comment tracer la distribution des valeurs dans la colonne des points :
#plot distribution of values in points column df['points'].plot(kind='kde')
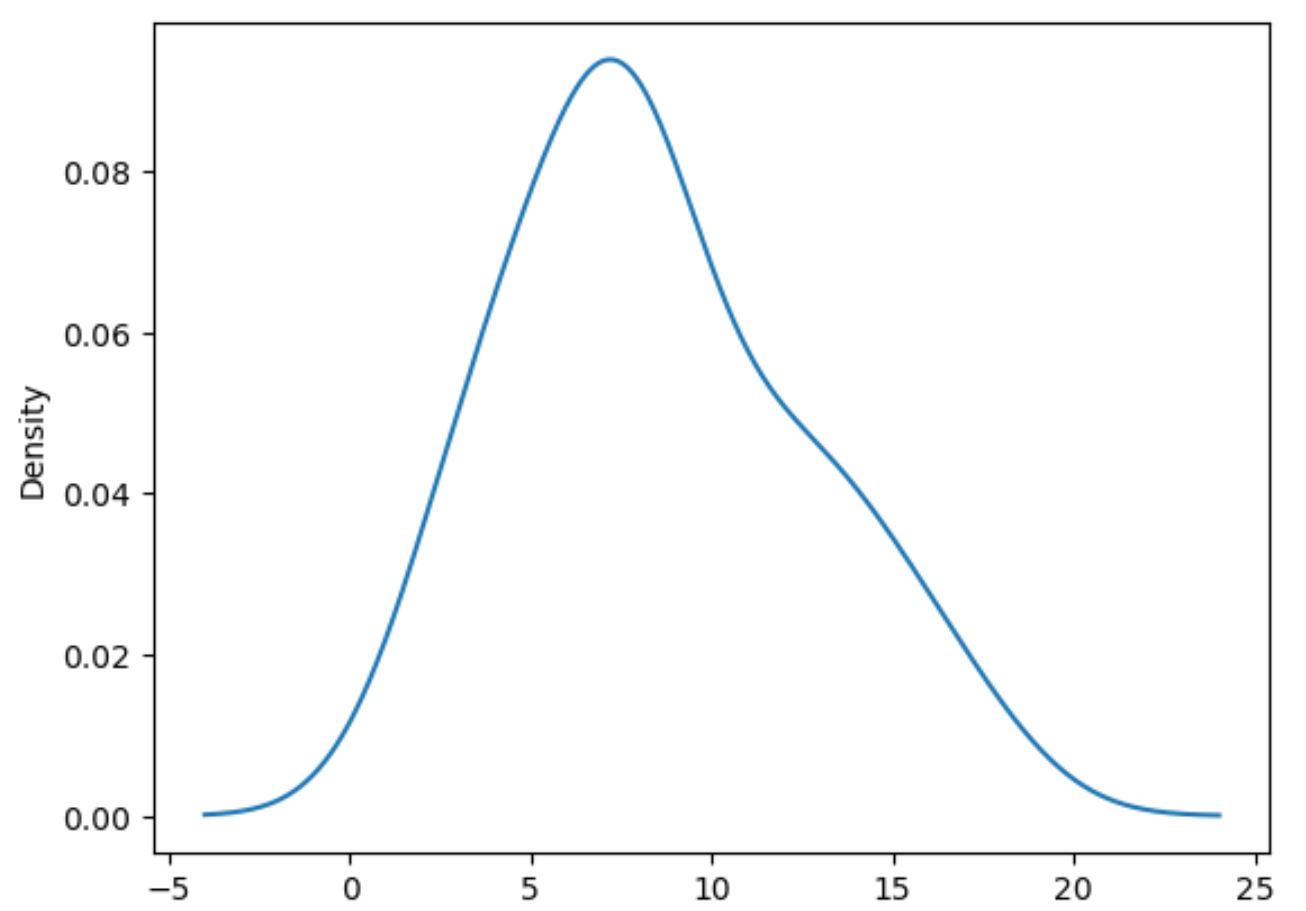
Notez que kind=’kde’ indique aux pandas d’utiliser l’estimation de la densité du noyau , qui produit une courbe lisse qui résume la distribution des valeurs d’une variable.
Si vous souhaitez plutôt créer un histogramme, vous pouvez spécifier kind=’hist’ comme suit :
#plot distribution of values in points column using histogram df['points'].plot(kind='hist', edgecolor='black')
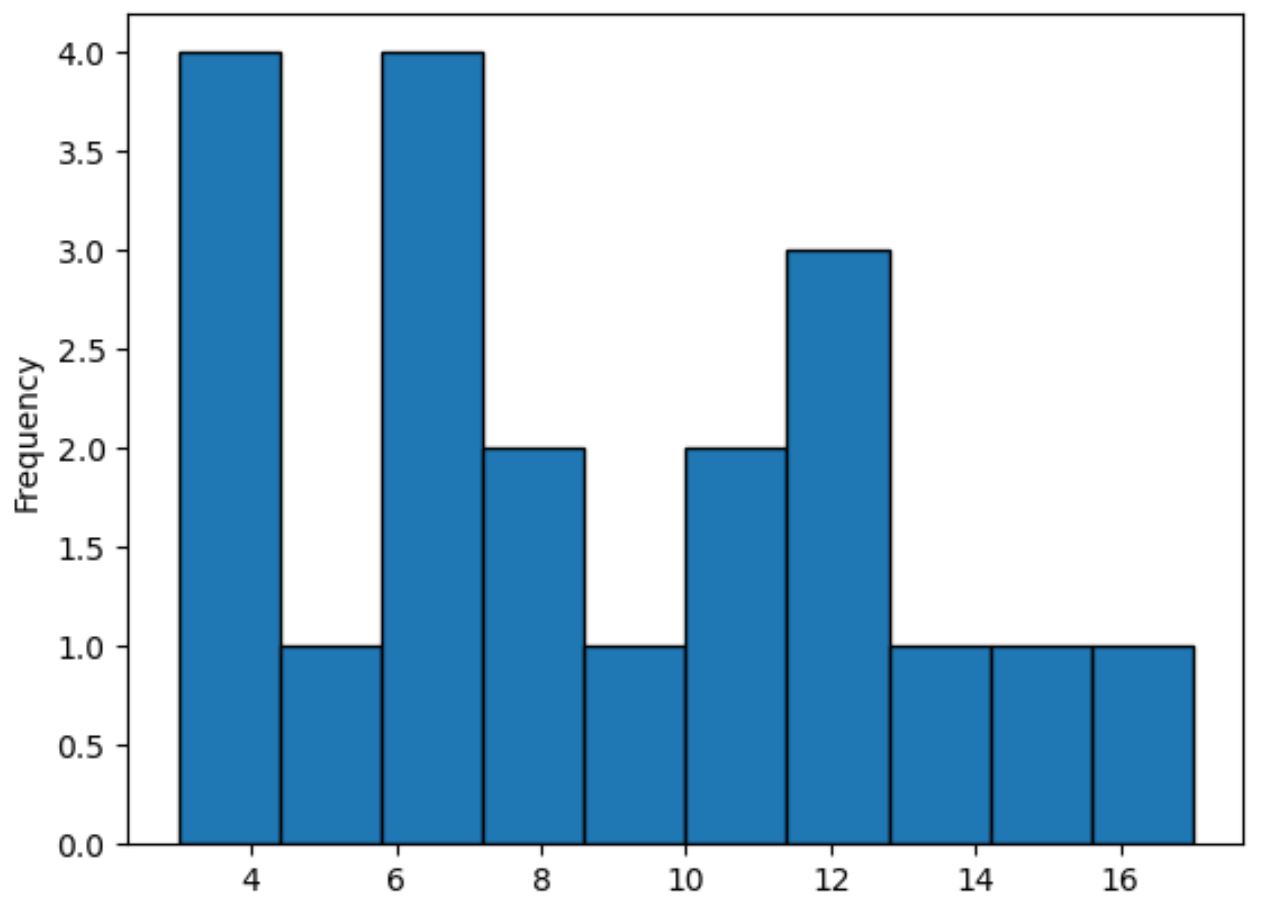
Cette méthode utilise des barres pour représenter les fréquences des valeurs dans la colonne de points , par opposition à une ligne lisse qui résume la forme de la distribution.
Exemple 2 : tracer la distribution des valeurs dans une colonne, regroupées par une autre colonne
Le code suivant montre comment tracer la distribution des valeurs dans la colonne des points , regroupées par la colonne de l’ équipe :
import matplotlib.pyplot as plt #plot distribution of points by team df.groupby('team')['points'].plot(kind='kde') #add legend plt.legend(['A', 'B'], title='Team') #add x-axis label plt.xlabel('Points')
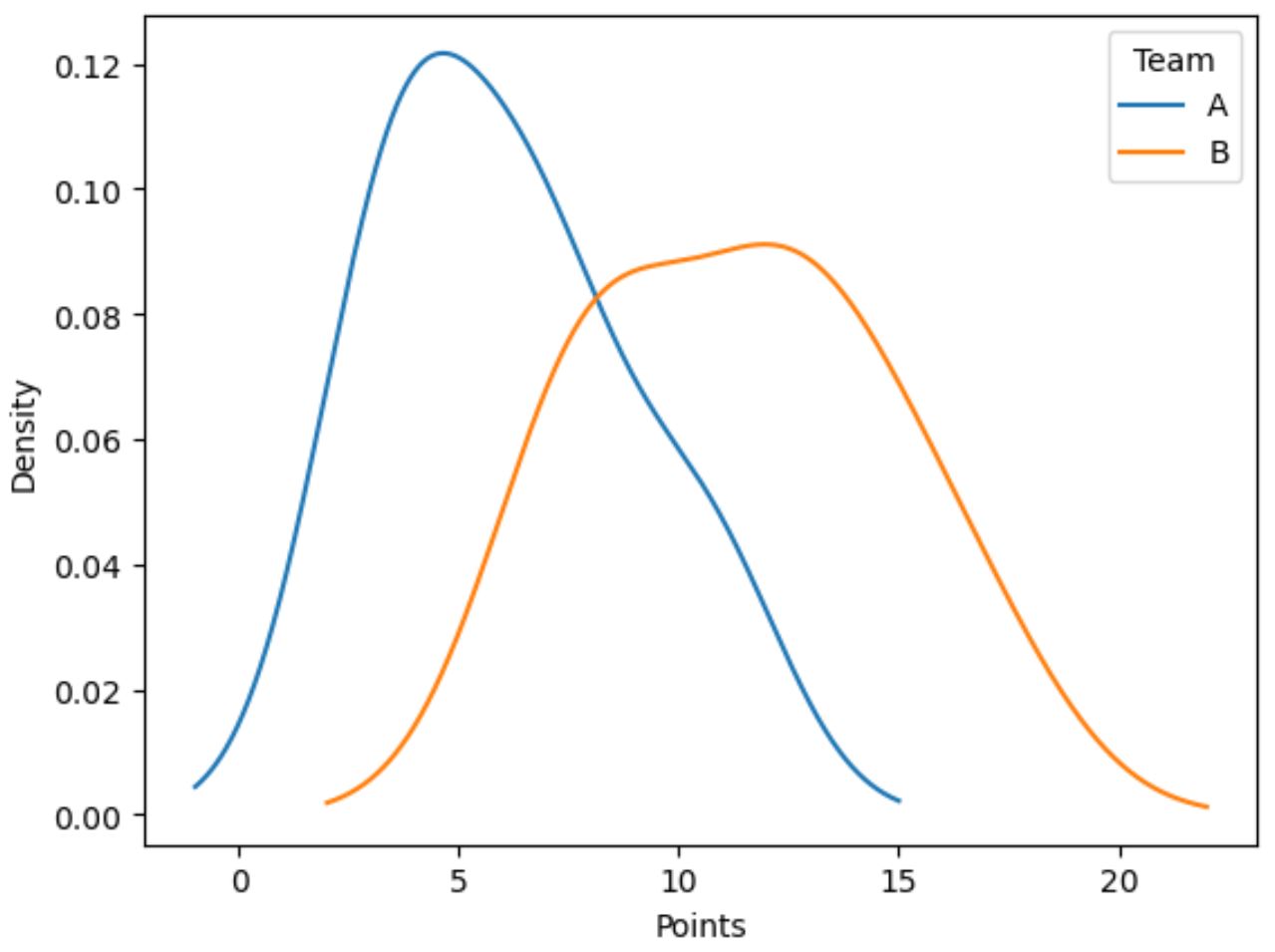
La ligne bleue montre la répartition des points des joueurs de l’équipe A tandis que la ligne orange montre la répartition des points des joueurs de l’équipe B.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans les pandas :
Comment ajouter des titres aux parcelles dans Pandas
Comment ajuster la taille de la figure d’un tracé de pandas
Comment tracer plusieurs DataFrames Pandas dans des sous-parcelles
Comment créer et personnaliser des légendes de tracé dans Pandas
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus