
Régression de crête dans R (étape par étape)
La régression Ridge est une méthode que nous pouvons utiliser pour ajuster un modèle de régression lorsque la multicolinéarité est présente dans les données.
En un mot, la régression des moindres carrés tente de trouver des estimations de coefficients qui minimisent la somme des carrés résiduels (RSS) :
RSS = Σ(y je – ŷ je )2
où:
- Σ : Un symbole grec qui signifie somme
- y i : la valeur de réponse réelle pour la ième observation
- ŷ i : La valeur de réponse prédite basée sur le modèle de régression linéaire multiple
À l’inverse, la régression de crête cherche à minimiser les éléments suivants :
RSS + λΣβ j 2
où j va de 1 à p variables prédictives et λ ≥ 0.
Ce deuxième terme de l’équation est connu sous le nom de pénalité de retrait . Dans la régression de crête, nous sélectionnons une valeur pour λ qui produit le MSE de test (erreur quadratique moyenne) le plus bas possible.
Ce didacticiel fournit un exemple étape par étape de la façon d’effectuer une régression de crête dans R.
Étape 1 : Charger les données
Pour cet exemple, nous utiliserons l’ensemble de données intégré de R appelé mtcars . Nous utiliserons hp comme variable de réponse et les variables suivantes comme prédicteurs :
- mpg
- poids
- merde
- qsec
Pour effectuer une régression de crête, nous utiliserons les fonctions du package glmnet . Ce package nécessite que la variable de réponse soit un vecteur et que l’ensemble des variables prédictives soit de la classe data.matrix .
Le code suivant montre comment définir nos données :
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
Étape 2 : Ajuster le modèle de régression Ridge
Ensuite, nous utiliserons la fonction glmnet() pour ajuster le modèle de régression Ridge et spécifier alpha=0 .
Notez que définir alpha égal à 1 équivaut à utiliser la régression Lasso et définir alpha à une valeur comprise entre 0 et 1 équivaut à utiliser un filet élastique.
Notez également que la régression de crête nécessite que les données soient standardisées de telle sorte que chaque variable prédictive ait une moyenne de 0 et un écart type de 1.
Heureusement, glmnet() effectue automatiquement cette standardisation pour vous. Si vous avez déjà standardisé les variables, vous pouvez spécifier standardize=False .
library(glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0)
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
Étape 3 : Choisissez une valeur optimale pour Lambda
Ensuite, nous identifierons la valeur lambda qui produit l’erreur quadratique moyenne (MSE) de test la plus faible en utilisant la validation croisée k-fold .
Heureusement, glmnet dispose de la fonction cv.glmnet() qui effectue automatiquement une validation croisée k fois en utilisant k = 10 fois.
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv.glmnet(x, y, alpha = 0)
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$lambda.min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
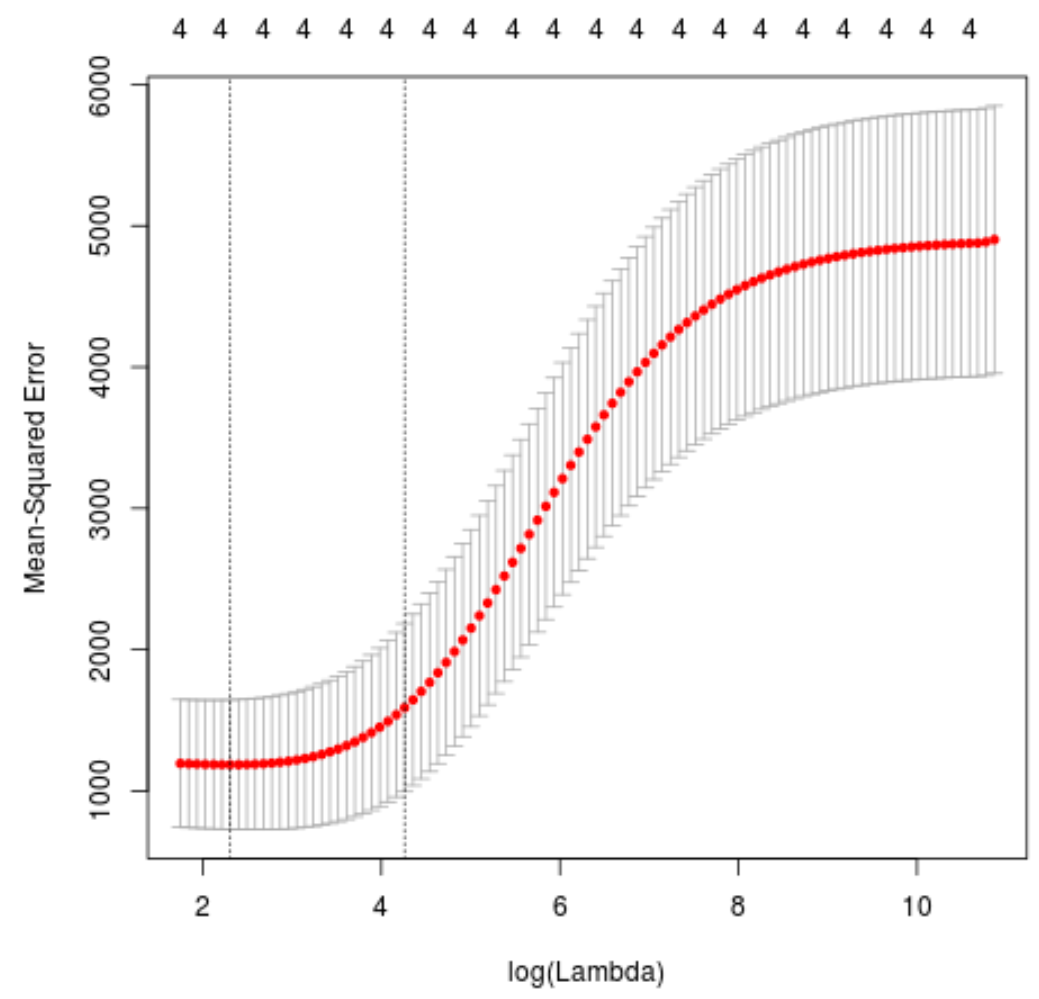
La valeur lambda qui minimise le test MSE s’avère être 10,04567 .
Étape 4 : Analyser le modèle final
Enfin, nous pouvons analyser le modèle final produit par la valeur lambda optimale.
Nous pouvons utiliser le code suivant pour obtenir les estimations de coefficients pour ce modèle :
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0, lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
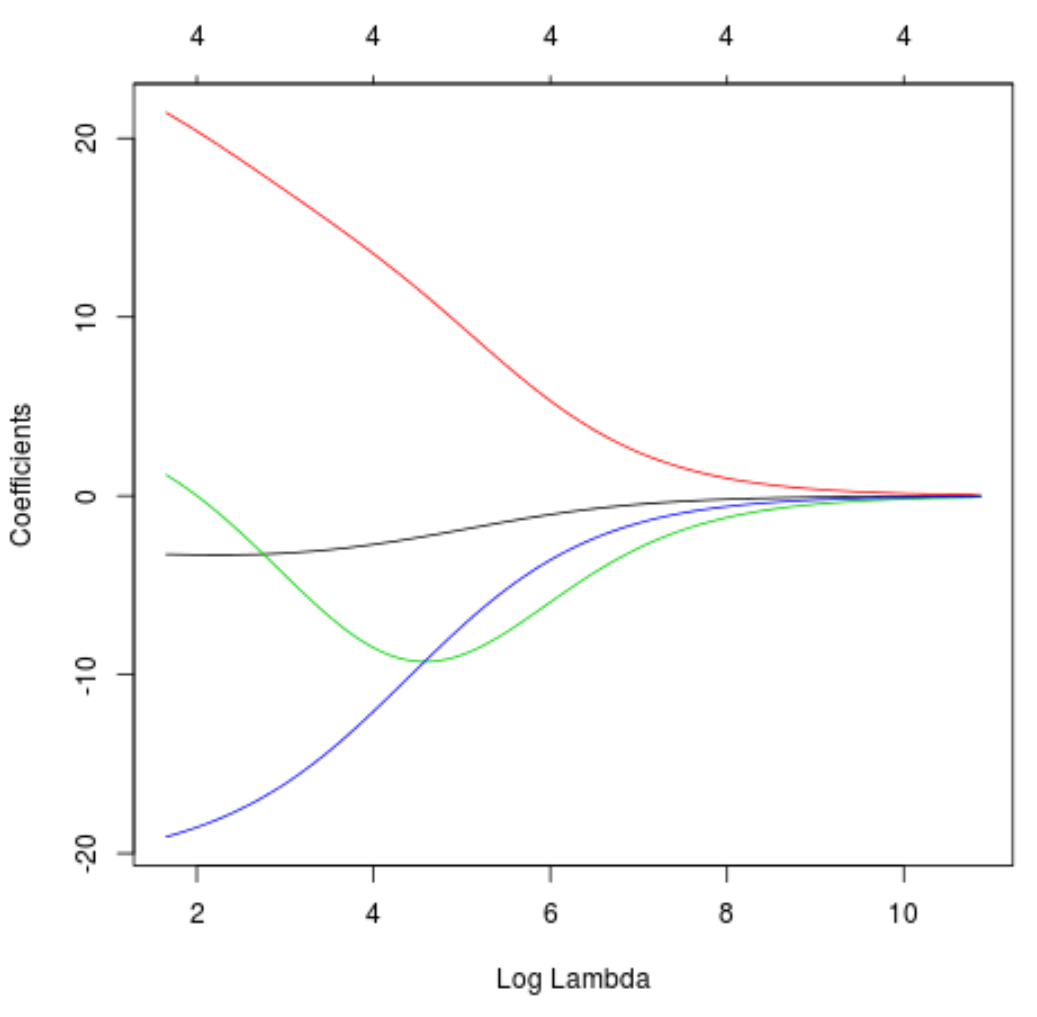
Nous pouvons également produire un tracé Trace pour visualiser comment les estimations du coefficient ont changé en raison de l’augmentation de lambda :
#produce Ridge trace plot
plot(model, xvar = "lambda")
Enfin, nous pouvons calculer leR-carré du modèle sur les données d’entraînement :
#use fitted best model to make predictions
y_predicted <- predict(model, s = best_lambda, newx = x)
#find SST and SSE
sst <- sum((y - mean(y))^2)
sse <- sum((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
Le R au carré s’avère être 0,7999513 . Autrement dit, le meilleur modèle a pu expliquer 79,99 % de la variation des valeurs de réponse des données d’entraînement.
Vous pouvez trouver le code R complet utilisé dans cet exemple ici .
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus