
Introduction à la régression logistique
Lorsque nous voulons comprendre la relation entre une ou plusieurs variables prédictives et une variable de réponse continue, nous utilisons souvent la régression linéaire .
Cependant, lorsque la variable de réponse est catégorique, nous pouvons utiliser la régression logistique .
La régression logistique est un type d’ algorithme de classification car elle tente de « classer » les observations d’un ensemble de données en catégories distinctes.
Voici quelques exemples d’utilisation de la régression logistique :
- Nous souhaitons utiliser le pointage de crédit et le solde bancaire pour prédire si un client donné fera défaut sur un prêt. (Variable de réponse = « Par défaut » ou « Aucun défaut »)
- Nous souhaitons utiliser la moyenne des rebonds par match et la moyenne des points par match pour prédire si un joueur de basket donné sera ou non repêché dans la NBA (Variable de réponse = « Drafté » ou « Non repêché »).
- Nous souhaitons utiliser la superficie en pieds carrés et le nombre de salles de bains pour prédire si une maison dans une certaine ville sera ou non répertoriée à un prix de vente de 200 000 $ ou plus. (Variable de réponse = « Oui » ou « Non »)
Notez que la variable de réponse dans chacun de ces exemples ne peut prendre qu’une des deux valeurs suivantes. Comparez cela avec la régression linéaire dans laquelle la variable de réponse prend une valeur continue.
L’équation de régression logistique
La régression logistique utilise une méthode connue sous le nom d’estimation du maximum de vraisemblance (les détails ne seront pas abordés ici) pour trouver une équation de la forme suivante :
log[p(X) / (1-p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p X p
où:
- X j : la j ème variable prédictive
- β j : estimation du coefficient pour la j ème variable prédictive
La formule sur le côté droit de l’équation prédit le log des chances que la variable de réponse prenne la valeur 1.
Ainsi, lorsque nous ajustons un modèle de régression logistique, nous pouvons utiliser l’équation suivante pour calculer la probabilité qu’une observation donnée prenne la valeur 1 :
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p X p / (1 + e β 0 + β 1 X 1 + β 2 X 2 + … + β p X p )
Nous utilisons ensuite un certain seuil de probabilité pour classer l’observation comme 1 ou 0.
Par exemple, nous pourrions dire que les observations avec une probabilité supérieure ou égale à 0,5 seront classées comme « 1 » et que toutes les autres observations seront classées comme « 0 ».
Comment interpréter le résultat de la régression logistique
Supposons que nous utilisions un modèle de régression logistique pour prédire si un joueur de basket donné sera ou non recruté dans la NBA en fonction de sa moyenne de rebonds par match et de sa moyenne de points par match.
Voici le résultat du modèle de régression logistique :
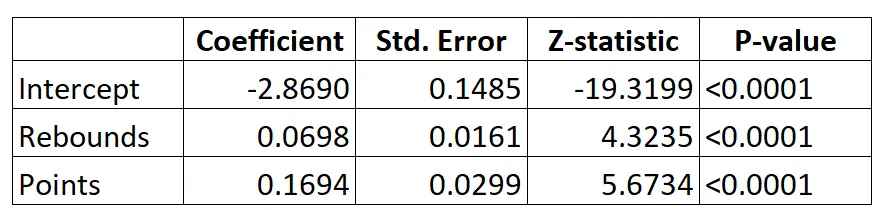
En utilisant les coefficients, nous pouvons calculer la probabilité qu’un joueur donné soit recruté dans la NBA en fonction de ses rebonds moyens et de ses points par match en utilisant la formule suivante :
P(Drafted) = e -2,8690 + 0,0698*(rebs) + 0,1694*(points) / (1+e -2,8690 + 0,0698*(rebs) + 0,1694*(points) )
Par exemple, supposons qu’un joueur donné réalise en moyenne 8 rebonds par match et 15 points par match. Selon le modèle, la probabilité que ce joueur soit recruté dans la NBA est de 0,557 .
P(Rédigé) = e -2,8690 + 0,0698*(8) + 0,1694*(15) / (1+e -2,8690 + 0,0698*(8) + 0,1694*(15) ) = 0,557
Puisque cette probabilité est supérieure à 0,5, nous prédisons que ce joueur sera repêché.
Comparez cela avec un joueur qui ne réalise en moyenne que 3 rebonds et 7 points par match. La probabilité que ce joueur soit recruté dans la NBA est de 0,186 .
P(Rédigé) = e -2,8690 + 0,0698*(3) + 0,1694*(7) / (1+e -2,8690 + 0,0698*(3) + 0,1694*(7) ) = 0,186
Puisque cette probabilité est inférieure à 0,5, nous prédisons que ce joueur ne sera pas repêché.
Hypothèses de régression logistique
La régression logistique utilise les hypothèses suivantes :
1. La variable de réponse est binaire. On suppose que la variable de réponse ne peut prendre que deux résultats possibles.
2. Les observations sont indépendantes. On suppose que les observations de l’ensemble de données sont indépendantes les unes des autres. Autrement dit, les observations ne doivent pas provenir de mesures répétées du même individu ni être liées les unes aux autres de quelque manière que ce soit.
3. Il n’y a pas de multicolinéarité grave entre les variables prédictives . On suppose qu’aucune des variables prédictives n’est fortement corrélée entre elles.
4. Il n’y a pas de valeurs aberrantes extrêmes. On suppose qu’il n’y a pas de valeurs aberrantes extrêmes ou d’observations influentes dans l’ensemble de données.
5. Il existe une relation linéaire entre les variables prédictives et le logit de la variable de réponse . Cette hypothèse peut être testée à l’aide d’un test de Box-Tidwell.
6. La taille de l’échantillon est suffisamment grande. En règle générale, vous devriez avoir un minimum de 10 cas avec le résultat le moins fréquent pour chaque variable explicative. Par exemple, si vous avez 3 variables explicatives et que la probabilité attendue du résultat le moins fréquent est de 0,20, alors vous devriez avoir une taille d’échantillon d’au moins (10*3) / 0,20 = 150.
Consultez cet article pour une explication détaillée de la façon de vérifier ces hypothèses.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus